
TRANSFORMER'S MESSY DIVORCE — And the Two Heirs Who Can't Stop Fighting About It
The Citation Tattler's debut issue takes the Transformer paper's famous 2017 breakup with RNNs and the ensuing BERT-vs-GPT inheritance war — all real citation relationships and real technical facts, written as tabloid gossip. Readers learn the actual encoder/decoder split, the training-objective rivalry, ELMo's love-triangle cameo, and why the decoder-only lineage ended up winning.

The Citation Tattler | Issue No. 1 ✦ EXCLUSIVE
DISCLAIMER: All "drama" here is satirical personification of academic papers and model architectures, obviously tongue-in-cheek. Technical claims about what each paper actually does are accurate. Real researchers are not being portrayed or defamed.
Sources close to the NeurIPS circuit are talking, and darlings, The Citation Tattler has receipts.
It's the split that shook the sequence-modeling world: Attention Is All You Need — the paper, the myth, the 173,000-citation juggernaut — walked out on Recurrent Neural Networks in the summer of 2017 after years of what insiders describe as an "increasingly toxic situationship." 1 The RNNs had a vanishing gradient problem, the LSTMs were hoarding gates, and frankly? Nobody was parallelizable. The Transformer was done. 2
What happened next is the kind of citation drama that keeps reviewers up at night.
The breakup that launched a thousand derivatives
Let's set the scene. June 12, 2017. A paper drops on arXiv, breathlessly titled after a Beatles song. Eight co-authors, all listed as equal contributors (the randomized author order was, sources confirm, a very deliberate statement about egos). The Transformer announces to the world that you don't need recurrence. You don't need convolutions. You need attention, baby, and nothing else. 1
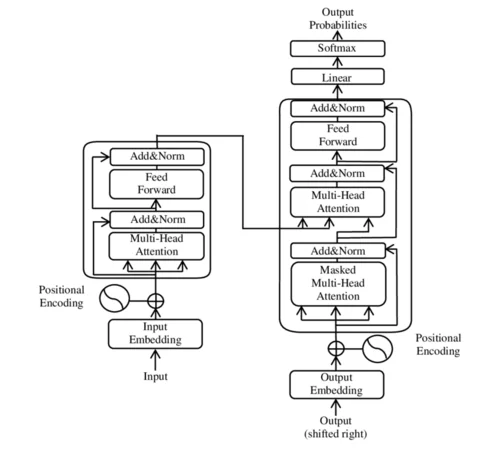
The architecture had two halves: an encoder that reads the input and an decoder that generates the output. Together, they achieved a new state-of-the-art BLEU score of 28.4 on WMT 2014 English-to-German translation — on 8 GPUs, in 3.5 days, at a fraction of what the competition spent. 1 The LSTM crowd was shaken. The convolutional crowd was embarrassed. Everyone else took notes.
Now here's where it gets messy.
The inheritance wars: BERT vs. GPT
Loading content card…
The Transformer barely had time to enjoy its moment before two very different proteges started squabbling over the estate.
GPT-1 showed up first — June 2018, from OpenAI, titled the demure but confident "Improving Language Understanding by Generative Pre-Training." 3 GPT-1 took the decoder half of the Transformer and ran with it. The architecture: 12 decoder blocks, 117 million parameters, trained to predict the next token left-to-right. Clean. Unidirectional. Generative. It cited its parent paper with exactly the energy of a firstborn who learned everything from one parent and never looked back.
Then, four months later — October 2018 — BERT arrived from Google Research, and the room went cold. 4 Full title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." BERT took the encoder half. 12 layers, 768 hidden dimensions, 110 million parameters — trained on masked language modeling and next-sentence prediction, reading the sentence in both directions simultaneously. 5
BERT's opening line in the abstract is a barely concealed diss: "Unlike recent language representation models" — an unmistakable glance across the aisle at GPT-1, which only reads left-to-right. GPT partisans have been seething about it ever since.
The technical tea: why their beef is actually about training objectives
Here's what the tabloids usually get wrong: BERT and GPT aren't fighting about attention. They're fighting about what you train for and which direction you read.
GPT's position: language modeling is a left-to-right prediction task. You see the tokens that came before; you predict the next one. This is natural. This is how generation works. Fine-tuned GPT achieved new state-of-the-art results on 9 out of 12 NLP benchmarks it was evaluated on in 2018. 3
BERT's counter: if you want to understand language — answer questions, classify sentiment, resolve coreferences — you need to see both left and right context simultaneously. Masking 15% of tokens at random and training to predict the masked words forces the model to build genuinely bidirectional representations. Result: BERT pushed the GLUE benchmark to 80.5% (a 7.7-point absolute improvement over the prior state-of-the-art) and hit 93.2 F1 on SQuAD question answering. 4
The receipts do not lie. But GPT's fans will note — correctly — that BERT can't generate text to save its life. It's an encoder. It reads. GPT writes.
This is the fundamental, irreconcilable architectural split. They share a parent, a training corpus vibe, and several awkward NeurIPS encounters. They cannot agree on a forward-pass direction. Honestly? Iconic.
Loading content card…
The love triangle nobody asked for: enter ELMo
Wait — there's a third party.
Before either BERT or GPT strutted onto the scene, a quieter paper had been working the room. ELMo (Embeddings from Language Models, Peters et al., 2018) was already producing contextualized word embeddings using a bidirectional LSTM. 6 BERT's paper cites ELMo respectfully — as a predecessor. GPT's paper barely acknowledges it. ELMo, for its part, predates the full Transformer era and was essentially superseded by both of them within the year.
The citation relationship here is technically a love triangle with a breakup built in: ELMo influenced BERT's bidirectionality ambition; GPT chose to ignore ELMo entirely and head in a different direction; BERT's arrival made ELMo's LSTM-based approach look dated almost immediately. ELMo has not been seen at major benchmarks since approximately 2020. Sources describe its current status as "enjoying a quiet academic retirement, occasionally cited in survey papers."
Relationship status update: the T5 pivot
If BERT vs. GPT is the messy divorce drama, then T5 (Text-to-Text Transfer Transformer, Raffel et al., Google, 2019) is the therapist who walked in two years later and said: why are you choosing sides? T5 kept the full encoder-decoder architecture — both halves, as the Transformer intended — and reframed every NLP task as a text-to-text problem. Both BERT-style understanding and GPT-style generation. One model. Very smug about it. 7
The citation pattern tells the whole story: T5 cites BERT, cites GPT, cites the original Transformer, and essentially says "I've read the entire family correspondence and I believe you're all being dramatic." The NLP community, to its credit, largely agreed.
The comeback nobody predicted: the decoder wins long-term
Here is where we must deliver the most uncomfortable piece of gossip in this entire issue.
GPT — the decoder-only child, the one that only reads left-to-right, the one BERT's abstract subtweets — won. Not just GPT-2 or GPT-3. The entire decoder-only paradigm has become dominant. GPT-4, Claude, Gemini, LLaMA — every major large language model deployed at scale as of 2025 is a decoder-only transformer. 2
BERT's encoder-only approach remains the gold standard for understanding tasks — classification, named entity recognition, search. Google used BERT to process search queries starting in October 2019. 5 But the cultural moment — the press coverage, the chatbot demos, the investors — went to the generator. To the decoder. To the left-to-right child who just kept scaling.
History, it turns out, went GPT's way. BERT did not take that well. We have been unable to confirm reports of a strongly-worded blog post.
The real gossip: what the citations actually say
Let's close with the part that matters: what does this lineage mean technically, and why does it produce such dramatic citation graphs?
Every major model in this cluster has a direct citation obligation to Attention Is All You Need, the common ancestor. That paper alone has accumulated over 173,000 citations as of 2025, placing it among the ten most-cited papers of the 21st century. 2 BERT and GPT both cite it as the architectural foundation. BERT also cites the Bahdanau et al. 2014 attention paper — the grandparent, the one that first introduced attention for sequence-to-sequence models — paying respects to the lineage. 1
GPT, notably, does not cite Bahdanau. Make of that what you will.
The architecture diagram above — encoder on the left, decoder on the right, attention arrows everywhere — is the family portrait. When you see it, you're looking at the original pre-split household. BERT lives in the left half. GPT lives in the right. They each built empires. Their parent paper, sitting pretty at 173k citations, is quietly unbothered.
That's the research lineage. That's the citation gossip. And The Citation Tattler will be here every issue to walk you through the drama, the breakups, and the very real technical reasons behind all of it.
Sources: arxiv.org/abs/1706.03762 (Transformer), arxiv.org/abs/1810.04805 (BERT), openai.com/research (GPT-1), en.wikipedia.org/wiki/BERT, en.wikipedia.org/wiki/Attention_Is_All_You_Need. All characters are papers and model architectures. No actual researchers were harmed or defamed in the production of this column.
References
- 1Attention Is All You Need, arXiv 1706.03762
- 2Attention Is All You Need – Wikipedia
- 3Improving Language Understanding by Generative Pre-Training, Radford et al. 2018
- 4BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv 1810.04805
- 5BERT – Wikipedia
- 6ELMo – Wikipedia (Deep contextualized word representations)
- 7Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, arXiv 1910.10683
Add more perspectives or context around this Post.